A bottom-up overview of the Apache configuration file
July 18, 2011
The Apache server is something that I've always just taken for granted. It's always there, it always works, and I never had to worry about it. I've downloaded and compiled it from source several times in my career, and it always comes right up, without much hassle, and does what it's supposed to do — that is, serve up web pages.
Still, the default configuration file is 410 lines. And that's not including 11 "extra" configuration files that the main configuration file references. There are actually another 895 lines worth of example configuration under "extra" — so in theory, you could have a 1,305-line Apache configuration file out of the box!
In spite of the stern admonition at the top of the main configuration file:
Do NOT simply read the instructions in here without understanding what they do. They're here only as hints or reminders. If you are unsure consult the online docs. You have been warned.
I must admit that I did exactly that for many, many years. Download Apache, compile it, tweak the configuration file just a bit, and let it run. Hopefully I didn't overlook anything...
A while back, though, I decided to make an effort to understand this labyrinthine configuration file. The online docs aren't as helpful as they might be, though. Although they serve as an excellent reference if you do remember how something works in the general sense, but just need a reminder of the actual syntax, there's no real "getting started" document. To get a real sense of how the whole thing worked, I decided to strip the configuration file down to the smallest one that would possibly work, and add features incrementally to see what each one did.
If you want to follow along, download the latest version of the Apache server from the main site and compile and install it. Delete (or rename) the default configuration file - you'll be creating a new one from scratch.
When httpd (Apache) comes online, it has to go and look for a configuration file. The default file is named "httpd.conf", and it is located under the server root directory, which is defaulted when Apache is compiled. The default server root varies from one platform to the next, and from one Apache version to the next - on Mac OS/X, for example, the httpd in /usr/sbin will look for its server root in /private/etc/apache2. CentOS defaults this to /etc/httpd. If you compile the latest 2.2.17 version of Apache, the default is /usr/local/apache2. If you run httpd with the "-V" flag, it will tell you what the defaults are:
debian:bin$ ./httpd -V
Server version: Apache/2.2.17 (Unix)
Server built: Apr 26 2011 15:12:23
Server's Module Magic Number: 20051115:25
Server loaded: APR 1.4.2, APR-Util 1.3.10
Compiled using: APR 1.4.2, APR-Util 1.3.10
Architecture: 32-bit
Server MPM: Prefork
threaded: no
forked: yes (variable process count)
Server compiled with....
-D APACHE_MPM_DIR="server/mpm/prefork"
-D APR_HAS_SENDFILE
-D APR_HAS_MMAP
-D APR_HAVE_IPV6 (IPv4-mapped addresses enabled)
-D APR_USE_SYSVSEM_SERIALIZE
-D APR_USE_PTHREAD_SERIALIZE
-D SINGLE_LISTEN_UNSERIALIZED_ACCEPT
-D APR_HAS_OTHER_CHILD
-D AP_HAVE_RELIABLE_PIPED_LOGS
-D DYNAMIC_MODULE_LIMIT=128
-D HTTPD_ROOT="/usr/local/apache2"
-D SUEXEC_BIN="/usr/local/apache2/bin/suexec"
-D DEFAULT_PIDLOG="logs/httpd.pid"
-D DEFAULT_SCOREBOARD="logs/apache_runtime_status"
-D DEFAULT_LOCKFILE="logs/accept.lock"
-D DEFAULT_ERRORLOG="logs/error_log"
-D AP_TYPES_CONFIG_FILE="conf/mime.types"
-D SERVER_CONFIG_FILE="conf/httpd.conf"
Example 1: Default Apache Configuration
Although you can override the location of the server root or just the configuration file, it's easiest to just work in the default directory with the default configuration file.
You may be surprised just how small an Apache configuration file you can get away with. The smallest Apache configuration file that will (almost) work is this one single line:
Listen 80
The "Listen" line is required, and tells the server what port it should listen on. If you omit the listening port (i.e. create an empty config file), httpd will shut down with:
sh-3.2# ./httpd no listening sockets available, shutting down Unable to open logs
Example 2: Trying to start Apache with no configuration file
You'll need to be root to start the server up on port 80 - if you're any other user, you'll get an error message when you try:
debian:bin$ ./httpd httpd: Could not reliably determine the server's fully qualified domain name, using 127.0.0.1 for ServerName (13)Permission denied: make_sock: could not bind to address [::]:80 (13)Permission denied: make_sock: could not bind to address 0.0.0.0:80 no listening sockets available, shutting down Unable to open logs
Example 3: Trying to start Apache as non-root user when the listen port is a privileged port
This is because, for (outdated) security reasons, only root can start up sockets that listen on so-called "privileged" ports < 1024.
So, if you go ahead and become root, the one-line configuration file from listing 1 almost works. If you create an httpd.conf file with just a listening port as shown above in listing 1, become root, and start up the server, the daemon will appear to start up, but you'll see this in the error log:
[Thu Jun 02 10:31:14 2011] [alert] (2)No such file or directory: getpwuid: couldn't determine user name from uid 4294967295, you probably need to modify the User directive [Thu Jun 02 10:31:15 2011] [alert] Child 941 returned a Fatal error... Apache is exiting!
Example 4: Trying to start Apache with just a listening port
and the httpd process will not be running.
What is this trying to tell you? Well, although root is the only user that can start up a process on a port < 1024, it's a bit of a security hole to actually run the server as root. If the server itself is somehow compromised, the compromising attacker will have root access to the system. Although you don't want to be compromised in general, you REALLY don't want root to be compromised. Therefore, you must supply the name of a user ID to switch to as soon as the listening port has been established.
Actually, you can make the one-line configuration file above work, and serve up documents, by changing the port number to a non-privileged port, like 8080, and running as a non-privileged user. You'll have to make sure that the default directories are writable by the non-privileged user, though. However, this is an abnormal way to use Apache, so the rest of this document will asume that you're running the normal way — that is, starting as root, running on port 80, and then letting httpd switch to a non-privileged user.
So, at a minimum, you need:
Listen 80 User daemon
This tells Apache to switch to the user "daemon" (which must already exist) after starting up the main listening socket. As long as you supply these two values, Apache will start up and begin responding to browser requests. Technically speaking, Apache needs two additional pieces of information to function — it needs the location of the error log, and the location of the document root. The error log is the file it will use to notify you of any failures, and the document root is where it will look for the HTML documents it actually serves up. There are defaults for both of these compiled into httpd - verison 2.2.17 defaults this to /usr/local/apache2/logs/error_log and /usr/local/apache2/htdocs. If you want to change either (or just make their locations more explicit — a good practice!), add the following two lines to the configuration file:
ErrorLog /usr/local/apache2/logs/error_log DocumentRoot /usr/local/apache2/htdocs
However, if you start up this server, put a web page into /usr/local/apache2/htdocs, and try to load it, you may not be very impressed with the results - depending on how you built Apache, the page may be returned as text, not HTML. What's wrong here? A look at the response headers provides a clue:
debian:conf$ wget -S -O - http://localhost/index.html --2011-06-02 10:59:19-- http://localhost/index.html Resolving localhost... ::1, fe80::1, 127.0.0.1 Connecting to localhost|::1|:80... connected. HTTP request sent, awaiting response... HTTP/1.1 200 OK Date: Thu, 02 Jun 2011 15:59:19 GMT Server: Apache/2.2.17 (Unix) Last-Modified: Thu, 02 Jun 2011 15:46:14 GMT ETag: "175800-70-4a4bc89781d80" Accept-Ranges: bytes Content-Length: 112 Keep-Alive: timeout=5, max=100 Connection: Keep-Alive Content-Type: text/plain ...
Example 5: Retrieving a file from the server
The file is served up as Content-Type text/plain, which the browser renders literally.
This may or may not have worked for you - the difference is whether or not you built Apache as a modular server or not. If you downloaded it and compiled it from source, unless you explicitly asked that it be built as a modular server, you built it with all of the standard modules included. However, if you're using the default Apache instance that came with your OS (like the one in Mac OS/X or CentOS), you're working with a modular server.
What is a "modular" server? Well, Apache all by itself doesn't do much, but instead delegates all of its functionality to external modules. As you see above, even fundamental functionality like making a web page appear as HTML is delegated to modules which are not in Apache's core. When you build Apache, you can either have it compile modules into the main executable, or create a miniature executable that will load all of its required modules at runtime. If you do this (or if you use a provided Apache that did this), you need to explicitly list the modules to load in the configuration file. I'll show you how to do this, and which modules you need to load, below.
Additionally, if you try running a non-modular server outside of the default configuration directory that "make install" created for you, you'll get an error when you try to start it up about a file named "mime.types". What happened here is that Apache, by default, compiles in the very useful module mod_mime - which is the one that recognizes that ".html" files should be returned as type "text/html". It also assumes that it will be able to find a file name "mime.types" in the default configuration directory. There's one supplied by default in the Apache installation directory.
In order to have Apache serve up HTML as it should, you need to tell it to serve up files as text/html:
Listen 80 User daemon DefaultType text/html
After you've made this change, you need to inform the Apache server that its configuration file has been modified. The most straightforward way to do this is to stop and restart the main httpd executable that runs Apache. However, a quicker way to force Apache to re-read its configuration file is:
debian:conf$ ps -fe | grep httpd root 3413 1 0 21:08 ? 00:00:00 /usr/local/apache2/bin/httpd -k start daemon 3414 3413 0 21:08 ? 00:00:00 /usr/local/apache2/bin/httpd -k start daemon 3415 3413 0 21:08 ? 00:00:00 /usr/local/apache2/bin/httpd -k start daemon 3416 3413 0 21:08 ? 00:00:00 /usr/local/apache2/bin/httpd -k start daemon 3417 3413 0 21:08 ? 00:00:00 /usr/local/apache2/bin/httpd -k start daemon 3418 3413 0 21:08 ? 00:00:00 /usr/local/apache2/bin/httpd -k start daemon 3420 3413 0 21:08 ? 00:00:00 /usr/local/apache2/bin/httpd -k start daemon 3423 3413 0 21:08 ? 00:00:00 /usr/local/apache2/bin/httpd -k start debian:conf$ kill -hup 3413
Example 6: Restarting a running Apache process
replace "3413" with the actual parent process. The subprocesses are all children, and they'll pick up the change to the parent process automatically. This works just fine - unless you made a mistake in the configuration file itself. If you did, then Apache will just silently and mysteriously die. Therefore, keep a close eye on the error log whenever you do a "kill -hup" on the Apache parent process.You may have to clear your browser cache to see this, or any other Apache server change, take effect, even after you bounce the server - browsers are pretty good (bad?) about loading things from cache whenever possible.
At this point, you have a working Apache instance with just three lines of configuration. It will serve up any HTML files from /usr/local/apache2/htdocs.
Early versions of the NCSA httpd server that Apache was originally based upon would have exposed a pretty serious security hole with this configuration, though - the browser could request "../../../etc/passwd" and the server would have uncomplainingly returned it. Apache has plugged this security hole since its first release by ignoring these sorts of directory metacharacters - still, the Apache people suggest that you include a restrictive security configuration on your root directory, and then explicitly open up additional directories on an as-needed basis:
<Directory /> Order deny,allow Deny from all </Directory>
(notice that there's no space after the comma - Apache will return an error if there is one).
This is the first use in this article of Apache's grouping directives - the directives inside the <Directory> tags apply to the named directory - in this case, the root directory and all of its subdirectories.
Note also that all of the configuration files preceding the one in listing 5 will work on a "stripped-down" apache, with no modules loaded. However, the Order directive belongs to the mod_authz_host module. If you're using a stripped-down modular Apache (such as the one that comes bundled with Mac OS/X or CentOS), you'll need to insert that module first:
LoadModule authz_host_module modules/mod_authz_host.so
If you did the default compile from source, you don't need to add this configuration directive. This configuration, of course, will deny access to everything to everybody, which is probably not what you want (I assume...) So, go ahead and reinstate access to everything under htdocs:
<Directory "/usr/local/apache2/htdocs"> Order allow,deny Allow from all </Directory>
This explicitly states that nobody should have access to any file on this server except for those under the DocumentRoot. The "Order" directive just states whether to check the allow rules first, or the deny rules first - either way, all applicable rules will be checked before the request is disposed. The Allow and Deny directives technically accept an IP range; "all" means all IP addresses. You can narrow this to any range or specific IP addresses you like, and you can have as many Allow or Deny directives as you need to implement whatever level of IP address filtering you need. I've been driven crazy by comment spammers while maintaining this blog - since I don't want to introduce an annoying captcha, I've been playing whack-a-mole trying to deny their IP addresses this way.
This restriction module is "authz_host" - i.e. authorize hosts. Another authorization method available to Apache administrators is user-based authorization. This is made available by the authz_user module:
LoadModule authz_user_module libexec/apache2/mod_authz_user.so
Now you can use the "Require" directive to require that a user be authenticated successfully before being allowed access to a resource collection (again, identified by a Directory):
<Directory "/usr/local/apache2/htdocs/private"> Require user jdavies </Directory>
This configuration (which will fail) leaves out a couple of key points, though - first of all, how should the user prove that he is, in fact, "jdavies", and how should the server verify that this is true?
The first question is resolved by the AuthType directive. The most basic AuthType available is, naturally enough, "basic" authentication. What this says is that the client must provide, through an HTTP request header, a username/password pair. The password itself is Base64 encoded to guard against casual observation - but be aware that Base64 decoding is very, very easy to do, and provides no protection against a malicious eavesdropper.
The second question — how can the server verify that the user is who he says he is — can be resolved by the AuthUserFile directive. This specifies a path, on the server's file system, to a list of username and password pairs. For security reasons, though, the password itself is not stored in the file but instead, a one-way hash of the password is. This is sufficient for authentication purposes - the user sends the actual password, base64 encoded, and the server base64 decodes it, hashes it, and compares the hashes - if they match, then the password must have been correct. In this way, the server doesn't ever need to store the actual password.
Creating these hashes is fairly complex, and has to be done just right - fortunately, Apache supplies a utility called "htpasswd" to create these user files.
debian:conf# htpasswd -b -c users jdavies password Adding password for user jdavies debian:conf# cat users jdavies:gDKuSixaoKfPk
Example 8: Creating an htpasswd file
Note the "-c" flag to create a new file. You'll need to supply this the first time you create this file, but never again afterwards, or you'll clobber it (and wipe out all user accounts in the process). This is actually pretty annoying, and will almost certainly bite you at least once as an Apache admin. For at least this reason, get in the habit of backing up your config files.
Once the users file is created, add, the directives:
<Directory "/usr/local/apache2/htdocs/private"> AuthType Basic AuthName "Restricted Resource" AuthUserFile /etc/apache2/users Require user jdavies </Directory>
LoadModule auth_basic_module libexec/apache2/mod_auth_basic.so LoadModule authn_file_module libexec/apache2/mod_authn_file.so
Note: authz is short for authorization - "can the user do this?", and authn is short for authentication - "is the user who he/she says he/she is?"
If a browser requests <server>/private/* now, the server will respond with a 401 authentication required error. Browsers are smart enough to interpret this as a login challenge, and present a login dialog box:
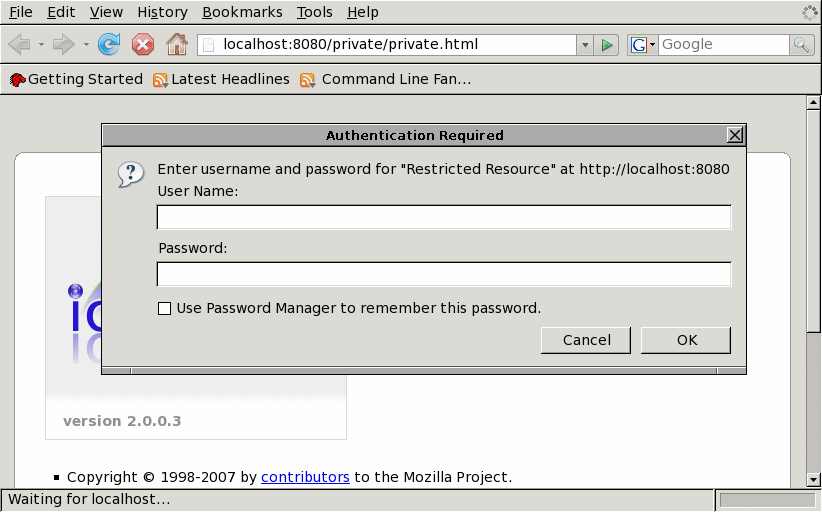
The user will input a user name and password here, which will be returned in an "Authorization" request header:
GET /private/index.html HTTP/1.1 Host: localhost Connection: keep-alive Cache-Control: max-age=0 Authorization: Basic amRhdmllczpwYXNzd29yZA== ...
Example 9: Requesting a protected file
Base64 decoding the authorization string gives:
jdavies:password
The server then looks in /etc/apache2/users for a line starting with "jdavies", hashes the given password, and compares it to the hashed password in the file. If they match, the request is permitted.
Notice in listing 10 that the directory "private" was given as a full path from root. You can actually shorten that a bit by using the "Location" directive instead. Apache's "Directory" directive is always relative to your file system - "Location" is relative to the document root. So, instead, you can write:
<Location "/private"> AuthType Basic AuthName "Restricted Resource" AuthUserFile /etc/apache2/users Require user jdavies </Directory>
Using basic authentication against a "users" file requires that the users file itself be searched every time a protected resource is requested. As the Apache documentation states, searching a large text file is slow - they suggest a dbm (Berkeley Database) file for a large user store. A more enterprise-grade solution is authentication/authorization against an LDAP data store, which is supported by Apache's mod_authnz_ldap module.
At this point, your Apache server accepts plaintext HTTP connections and serves up documents. If the browser requests a document that you've marked as confidential, it will demand a user name and password before proceeding, and authenticate that user with either a username/password file or an LDAP data store.
However, it won't accept HTTPS connections. For one thing, it's not listening on the HTTPS port of 443 - but more fundamentally, in order to support HTTPS, a server needs to be prepared to present a certificate with its own server's name on it.
HTTPS is HTTP over SSL - in other words, the client and the server must negotiate a secured SSL channel before the HTTP part can begin. In order to do so, they must undergo a key exchange process which involves an asymmetric encryption algorithm and a public key, which the server must present. A certificate serves two fundamental purposes in SSL - first, it identifies the public key that the client (i.e. the browser) must use to encrypt the session key, and it also identifies the identity of the server so that the client can verify that it's really talking to the server it expects and not a malicious man-in-the-middle.
This second purpose is accomplished in two stages. First, the client checks to see that the name in the certificate matches the domain name of the server. Of course, this check is pointless if the name can be forged - so the certificate must be digitally signed (using, again an asymmetric encryption algorithm - in most cases, the same one that performs key exchange) by a certificate authority trusted by the client. Browsers come preconfigured with a list of trusted commercial certificate authorities and the public keys that can be used to verify a trust relationship.
Since commercial certificate authorities are expensive, for the purposes of this article, I'll just show you how to create a "self-signed" certificate and install it in your Apache server. A self-signed certificate is one which is signed by its own public key and - obviously, since anybody can create one of these with minimal effort, you shouldn't necessarily trust one unless you've verified it through some other means.
The OpenSSL project is a free, open-source implementation of the SSL algorithm/protocol. It also comes with several helper utilities, including one that can be used to create certificates. In fact, the helper utilities can even be used to create a certificate authority that signs other certificates - for now, though, just keep it simple and create a self-signed certificate.
debian:~ jdavies$ openssl req -x509 -newkey rsa:512 -out selfsigned.crt \ -outform pem -keyout selfsigned.key -keyform pem Generating a 512 bit RSA private key ..........++++++++++++ ............................................++++++++++++ writing new private key to 'selfsigned.key' Enter PEM pass phrase: password Verifying - Enter PEM pass phrase: password ----- You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]:US State or Province Name (full name) [Some-State]:TX Locality Name (eg, city) []:Plano Organization Name (eg, company) [Internet Widgits Pty Ltd]:2xOffice Organizational Unit Name (eg, section) []:Architecture Common Name (eg, YOUR name) []:localhost Email Address []:joshua.davies.tx@gmail.com
Example 10: Creating a self-signed SSL certificate
The last 7 prompts establish the "distinguished name" in the certificate - the most important of these, from an HTTPS perspective, is the Common Name (the second one up from the bottom). Notice that it asked me for "MY name", but I gave it "localhost" instead. This is because this is what the browser will look for when it tries to verify the authenticity of the certificate - this must match the actual domain name that it requested, or an error will result.
This process generates two files named "selfsigned.crt" and "selfsigned.key". The key file is sensitive, and should be protected:
chmod 400 selfsigned.key
This makes the key file unreadable by any user except the owner, and unwritable by any user regardless.
The certificate file is Base64-encoded DER - you can examine its contents using the OpenSSL package.
sales:~ joshuadavies$ openssl x509 -noout -subject -issuer -in selfsigned.crt \ -inform pem subject= /C=US/ST=TX/L=Plano/O=2xOffice/OU=Architecture/CN=localhost/emailAddress=joshua.davies.tx@gmail.com issuer= /C=US/ST=TX/L=Plano/O=2xOffice/OU=Architecture/CN=localhost/emailAddress=joshua.davies.tx@gmail.com
Example 11: Examining the self-signed certificate
The certificate includes the public key, and the key file includes the private key - the private key is used to decrypt anything encrypted with the public key, so Apache needs to have access to it, but nobody else should. Once this is done, point Apache to it and enable SSL:
LoadModule ssl_module libexec/apache2/mod_ssl.so Listen 443 SSLEngine on SSLCertificateFile "/usr/local/apache2/conf/selfsigned.crt" SSLCertificateKeyFile "/usr/local/apache2/conf/selfsigned.key"
This includes the ssl module, adds a listening port of 443, enables SSL, and describes the location of the certificate and key file. Now, if you run or restart httpd, you can request documents via HTTPS and they'll be served up securely. Your browser will complain about the self-signed certificate, as it should, but you can ignore the warning and continue.
However, all is not well - if you try to turn around and request a plain-old HTTP document, you'll get an error message that varies from one browser to the next. Chrome's response is actually pretty descriptive:
Bad Request Your browser sent a request that this server could not understand. Reason: You're speaking plain HTTP to an SSL-enabled server port. Instead use the HTTPS scheme to access this URL, please. Hint: https://localhost/
Example 12: Requesting an HTTP document from an HTTPS-only server
The problem here is the "SSLEngine on" directive. This tells Apache to establish an HTTPS connection for all requests, even those that shouldn't have it, like plaintext HTTP ones. So, how can you turn on HTTPS for some documents but not for others? And how can you let the user select one or the other?
The answer goes back to the early days of Apache, when computing power was expensive. In those days, it was common to host multiple independent web sites from a single server. It was so common, in fact, that Apache had built-in support for this via the "Virtual host" directive. There was, of course, only one physical host, but the administrator could configure several virtual hosts, each with their own name and perhaps even IP address, which shared a single Apache instance. The Virtual Host directive allowed separate configuration areas to be created within a single configuration file so that the virtual hosts could be administered completely independently.
So what does this have to do with SSL? Well, if you want to run a server that speaks both HTTP and HTTPS, it's actually conceptually like running two separate servers. Apache makes the conceptual actual, and requires you to define a virtual host containing all of the SSL configuration directives:
Listen 443
<VirtualHost _default_:443>
SSLEngine on
SSLCertificateFile "/usr/local/apache2/conf/server.crt"
SSLCertificateKeyFile "/usr/local/apache2/conf/server.key"
</VirtualHost>
There's a LOT more to secure SSL setup, but this is the core of it. Consult the Apache docs for more information on Apache's SSL support. If you want a much more detailed description of SSL and HTTPS, take a look at my book.
Now that you have both a secure and a non-secure virtual host, you can set up different directories for each - one directory will only be served up securely, and one will be served up non-securely. You can freely mix and match, so that documents can exist in one or both. However, as configured right now, if a user requests a document that ought to be loaded securely over HTTP (for instance, a login page), you have two bad choices - return a stark 404 error message, or return the page non-securely.
Fortunately, the Apache people thought of that, too, and provided the "Redirect" directive that allows you to redirect requests for one document to another, internally. You can insert this directive to auto-redirect any non-secure request to a secure one:
Redirect permanent / https://server.name/
Be careful, though. If you just add this directive arbitrarily at the top level of your configuration file, it will work correctly — and redirect every request, including secure ones! The user will get stuck in a redirect loop and, if he's lucky, the browser will break him out of it.
Instead, define a special VirtualHost for http whose only purpose is to perform redirects:
NameVirtualHost *:80 <VirtualHost *:80> Redirect permanent / https://server.name/ </VirtualHost>
So, now you have a working server that serves up either secure or non-secure documents and lets you set up a password-protected area. Notice, however, that if you just enter the website address and don't request a specific document, nothing appears - this is fairly non-standard behavior as well. If a user just inputs a "bare" URL, they'll expect to be automatically redirected to some sort of a home page. This is where the DirectoryIndex directive comes in - if the user selects a directory in the document root, but doesn't specify a file, it indicates the name of a file to return that serves as the "index" of the directory. This terminology is a bit of a throwback to the days when a web server was just a document repository, and requesting a bare directory meant "show me a list of all the files in this directory". As such, most sites name the default file "index.html", although in general, the file in question isn't a index at all, but a welcome page.
DirectoryIndex index.html
At this point, you have an Apache server that can do a good job of serving up static websites. However, there aren't that many web sites that can be meaningfully maintained without some sort of scripting these days - even this simple blog requires some interactivity so that you can add comments, and so that I can maintain consistent headers and margins across all of the pages. Although for really big sites, you want to step outside of Apache and use a content management system for such functionality, you can go quite a ways with just plain-old Apache and CGI scripts.
See, there's nothing in the HTTP protocol that mandates that an HTTP request must serve up a static document from the local file system. The server must return an HTTP response, but how it decides what content to insert into that response is entirely up to it. The concept of CGI scripts is that, instead of having the server search its file system for a document to return, such as "index.html", it will instead run a program whose output is an HTML document (or an XML document, or even multimedia - HTTP doesn't care).
Such programs are called CGI scripts or "Common Gateway Interface" scripts. By default, Apache won't run scripts - you have to tell it specifically that you want it to via the directive:
ScriptAlias /cgi-bin /usr/local/apache2/cgi-bin
This tells Apache two things. First, any request for cgi-bin/* should be resolved relative to /usr/local/apache2/cgi-bin, not htdocs/cgi-bin (which would be the default without this directive). Second, anything under cgi-bin should be treated as a script and run rather than returned as a plain-old document. Note that, for security reasons, the path must be a full path; it can't be specified relative to the document or server root.
The script in question must follow certain conventions - its output must start with a line such as:
Content-type: text/html; charset=iso-8859-1
This is an HTTP header indicating the type of the response document. This must be followed by a blank line, by HTTP conventions - if you forget to do this, the browser will interpret everything (up until the first blank line) as an HTTP header. If you wanted to insert any additional headers (for instance, Content-Length, to be polite to the browser), you would insert them here as well before the blank line.
This blank line is followed, of course, by the content itself. The script can be written in any language that can be invoked as a script — Perl and Python are popular choices, but the default Apache installation includes a "test-cgi" script that uses the plain old /bin/sh shell to create its output. As long as the script produces a properly formed HTTP response, the browser won't be able to tell the difference between a scripted response and a static document.
There are some downsides to CGI scripts, of course — one of the most important being the performance hit on the server when it has to spawn an entire new process for each dynamic page requests. Although most industrial-strength websites these days use J2EE or ASP to serve up dynamic pages, it's nice to know that CGI scripts are still out there. If your needs are modest, you can actually get quite a bit done with simple CGI scripting — the blog you're reading is CGI based, for example.
Now you've got a pretty functional Apache server - you can serve up static documents and dynamic documents. You can see errors when they occur, by watching the error_log. One extremely useful bit of extra functionality here, though, is the access log, which for some reason Apache 2 does not enable by default (Apache 1 did). This directive enables the access log:
TransferLog logs/access_log
You will have to ensure that log_config_module is loaded in order to use this; it's included statically by default. This will log every single access request, along with its source IP address, date, the return status, and the length of the response by default — you can even have it log additional information including certain cookies if you configure it so.
If your site has more files than just HTML files (and most do - at the very least, you probably have a couple of .gif or .jpeg files), you need a way to indicate the type of file being returned. Remember back in Listing 4, when I talked about the default type that may or may not be needed, depending on the modularity of your Apache installation? Well, the mime_module that is built into the Apache server by default looks for a file named ${SERVER_ROOT}/conf/mime.types which associates each file extension with a MIME type. It looks like this:
application/andrew-inset ez application/applixware aw application/atom+xml atom application/atomcat+xml atomcat application/atomsvc+xml atomsvc ...
This just tells Apache that if the user requests a file whose extension is ".ez", it should return a Content-Type header of:
Content-Type: application/andrew-inset
And no, I have no idea what an "andrew inset" file is.
The more interesting, and more useful, entries appear toward the middle:
image/gif gif image/jpeg jpeg jpg jpe image/png png image/svg+xml svg svgz image/tiff tiff tif
Notice here that files with extensions ".jpeg", ".jpg" or ".jpe" are all associated with content type "image/jpeg".
This information is crucial to a browser for proper rendering — this is why it was necessary to insert the "Content-Type" header manually when writing CGI scripts as shown above; the browser needs to know how to interpret the bytes that follow, and mime.types can't help, since there's no meaningful file extension.
Believe it or not, there's still a lot more to the Apache configuration file that I haven't covered here, but this covers the most important parts. Apache can support WebDAV, user directories, auto indexing, and quite a bit more.
Add a comment:
Completely off-topic or spam comments will be removed at the discretion of the moderator.
You may preserve formatting (e.g. a code sample) by indenting with four spaces preceding the formatted line(s)

