An Illustrated Guide to the BEAST Attack
Recently, I was working on a security implementation for a system that didn't support TLS 1.1+. Of course, we know that being behind the times is always a Bad Thing in security circles; TLS 1.2 was officially published nearly six years ago, and the TLS working group has already begun formulating 1.3. Yet TLS 1.0 persists and is pretty much the default in most cases. Qualys labs reports that as of January, 2014, only 23% of websites support TLS 1.1. (25% support TLS 1.2; it's unclear how much overlap there is between the two, but since all known TLS 1.2 implementations also support TLS 1.1, I think it's safe to assume that the majority of these are the same sites). So, what's the danger?
TLS 1.1 was, in fact, a relatively minor upgrade to TLS 1.0; the only really significant change was in the way initialization vectors were computed for CBC mode. This must have been pretty important for the TLS working group to have created an entirely new specification just to change the way they were presented. So, what are these initialization vectors and just what do they do?
TLS is, in essence, a specification for the secure exchange of encryptions keys over a public channel. Once the keys are exchanged, symmetric (e.g. "classic") cryptography takes over and is responsible for securing the transmitted data. Protection against would-be eavesdroppers, then, is entirely in the hands of the encryption algorithm applied. There are lots of these symmetric algorithms — they're the fun part of cryptography, and cryptography researchers spend a lot of time designing (and trying to break) symmetric encryption algorithms. One such algorithm is IBM's Data Encryption Standard (DES). DES was the first computer-communications grade encryption algorithm and, although considered out of date these days, is still the de facto starting point for understanding modern encryption. It's also a good case for understanding what initialization vectors are, and why they're important.
I won't detail the DES algorithm here, but one important point about it is that it's a block encryption algorithm — meaning that it works on fixed-sized blocks of data. 8 bytes of it, to be precise. The DES algorithm takes as input 8 bytes of plaintext along with a key (also 8 bytes) and outputs 8 bytes of ciphertext. This ciphertext can be publicly transmitted and the sender can rest assured that nobody can recover the original plaintext unless they also have access to the same 8-byte key. Note that all block ciphers operate on precisely their block size - no more, no less. DES operates on 8-byte blocks, so the input must be exactly 8 bytes. If you don't have that much data that you want to encrypt, the input must be padded with "garbage" up to 8 bytes, and this must be done in such a way that the receiver knows which of potentially 7 bytes are garbage. If you have more, it must be split into multiple 8-byte blocks, each encrypted individually, the last one padded if the input doesn't happen to be an even multiple of 8 bytes. There are other block ciphers, including the current U.S. government Advanced Encryption Standard (AES), which have longer block sizes, but in all cases, there is a fixed block size.
One problem with block ciphers is that by nature, they must be
deterministic. Given the same pairs of 8-byte plaintext and 8-byte keys, they
MUST produce the same 8-byte ciphertext. For example, given the 8-byte
plaintext "sendhelp" and the 8-byte key "password", any compliant DES
implmentation must produce the 8 byte ciphertext df a1 16 88 92 5c ad 78.
This isn't a limitation of DES, this is a natural property of any block
encryption algorithm; in order to be decryptable (i.e. reversible), the
algorithm must be predictable in this way. Of course, given a different key,
say, "encodeme", the output would be completely different: bf ff 68 19 25 4b 30 a3.
However, if the same key is used to encrypt the same 8 bytes of data more than
once, the encrypted output will always be the same. This can give a potential
attacker a lot of information about the nature of the original transmission;
computer communications tend to be fairly repetetive. Consider the typical
HTML document... how many times does the 8-byte sequence <div><div>
occur?
To illustrate why this is problematic, consider
the following hypothetical: Dan suspects Bob of having an affair with his wife,
Kimberly. He knows that Bob always begins his letters with 'Dearest', but he
encrypts all of his communications. So, he wants to know if Bob is transmitting
"Dearest Kimberly". Coincidentally, Kimberly's name is exactly 8 characters
and falls on an 8-byte boundary in this contrived example, but it was encrypted
with the secret key 'password' which Dan can't guess. The first block,
"Dearest ", DES encrypts to f9 1b d5 c2 f6 42 2e 42. The second block, Kimberly,
DES encrypts to 94 04 8d d0 ca 9f f9 9c. Now, if Dan can see Bob's encrypted
connection (somehow - more on this later) and transmit whatever he wants and
have it encrypt while simultaneously viewing the encrypted output, he doesn't
have to guess the password. Instead, he can look at the second block Bob sent,
and then trick Bob into transmitting "Kimberly" and observe the output. If
the observed output matches the previously observer second block, he knows that
Bob is chatting with his wife.
Note that I'm using DES for this example, which is not considered secure
for modern cryptography purposes because the 8-byte key is too short, but that's
not why Dan is able to glean information about Bob's conversation — the
key was never compromised, and this same attack would work on any block cipher
algorithm.
This has been a well-known problem with block encryption algorithms for quite a while, so there are a lot of defenses against it. The most common (and, until TLS 1.2, the only available option for SSL/TLS) is called Cihper Block Chaining (CBC). The idea here is pretty simple; before encrypting a block, combine it with the one that came before it in a way that can be easily reversed at decryption time. In the case of CBC, this combining is done by XOR-ing the block with the one that came before it — this makes "uncombining"/separating it easy because XOR is self-reversing (that is: a xor b xor b = a).
However, as is always the case with security implementation, the devil is in the details. If every block is XOR-ed with the one that came before it, what do you do with the first block? The CBC solution is to prepend the data with a block a random data called the Initialization Vector (IV). This block is simply discarded by the receiver. The key difference between TLS 1.0 and TLS 1.1 (at least with regard to IV handling) is how this IV is transmitted. In TLS 1.0, the IV is actually considered a secret, and handled with the same care as the key; when both sides negotiate a key securely, they negotiate an IV at the same time. For the remainder of the session, the CBC residue is the previous (encrypted) block.
Sounds good, right? Well, you can be forgiven for thinking so — the designers of SSL thought so, too, and so did everybody else until Phil Rogaway documented a flaw in 2002. The flaw has to do with the combination of CBC mode and the fact that TLS (like any network communication protocol) splits data into transmittable "chunks". A 1000-byte message may be split into 10 100-byte packets for transmission reasons, each as an individual SSL packet. Logically, they behave as though the were one long message; in particular, the last eight bytes of packet n-1 is the CBC residue of the first eight bytes of packet n. This means that if an attacker can inject his own packets into the SSL stream, he'll know what CBC will be used to encrypt the beginning of his message.
This may strike you as a highly theoretical attack. In
addition to being able to attack the channel, the attacker must be able to
exploit this information. Since TLS includes a secure MAC, the attackers
packet will be immediately rejected, and the secure channel will be closed, so
he has only one packet with which to compromise the communications. Let's go
back to Dan, Bob and Kimberly. Now, Bob has wised up (I guess he's done this
sort of thing before) and started using CBC. He randomly generates an IV of
01 23 45 67 89 ab cd ef - now, 'Dearest ' is xored with it as shown in figure
1:
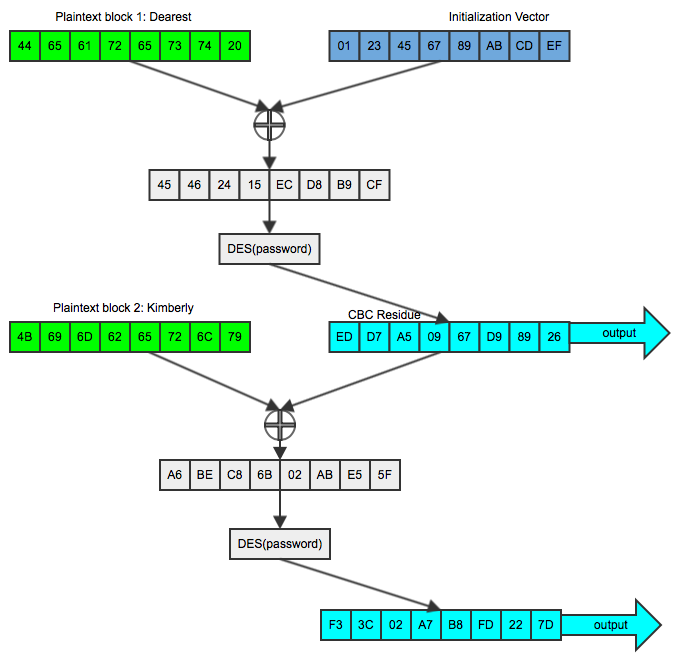
Figure 1: Encryption in CBC Mode
What Dan sees by sniffing Bob's traffic is ed d7 a5 09 67 d9 89 26 f3 3c 02 a7
b8 fd 22 7d. If he tries to do a packet injection attack and trick Bob into
encrypting Kimberly so that he can compare it against the second block
(f3 3c 02 a7 b8 fd 22 7d), it won't work this time, because Bob's TLS
implementation will XOR it with the previous block. Let's say for the sake of
argument that this CBC residue is the improbable fe dc ba 98 76 54 32 10.
If Dan injects "Kimberly" into Bob's plaintext, he'll see an unrelated block
of output as illustrated in figure 2:
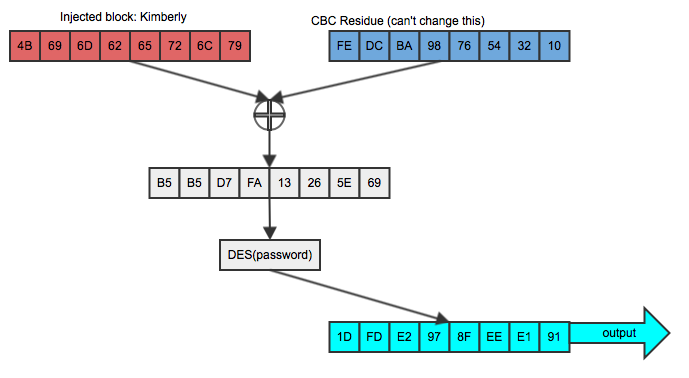
Figure 2: Attempting to inject known plaintext
This doesn't compare equally to the second block of the original ciphertext and (if CBC is doing its job at all) is useless to Dan in trying to determine if the two are equal. But Dan is clever, and he knows a thing or two about XOR; specifically that if you XOR the same value twice, the second undoes the effect of the first. So, knowing that his chosen plaintext will be xor-ed with the (known) CBC residuefe dc ba 98 76 54 32 10, he first XORs "Kimberly"
with that, as repeated in figure 3:
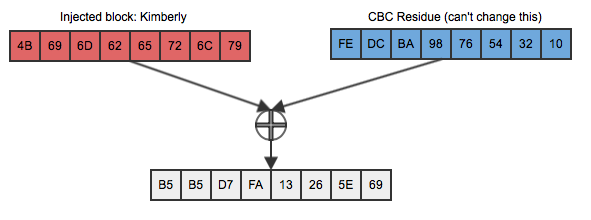
Figure 3: First input
And then he XORs this again with the CBC residue of the second block (the one he wants to compare against), which was the output value of the first block, as shown in figure 4:
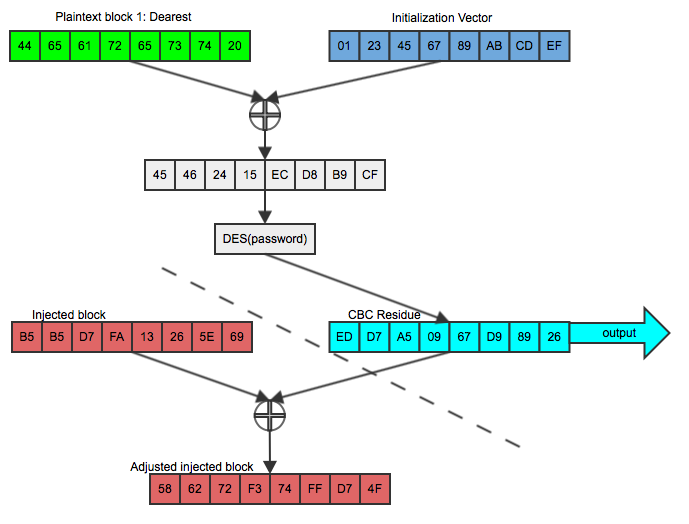
Figure 4: Taking advantage of a known CBC residue
If he can then trick Bob into encrypting THIS, using the same key and the (now known) CBC residue, as shown in figure 5:
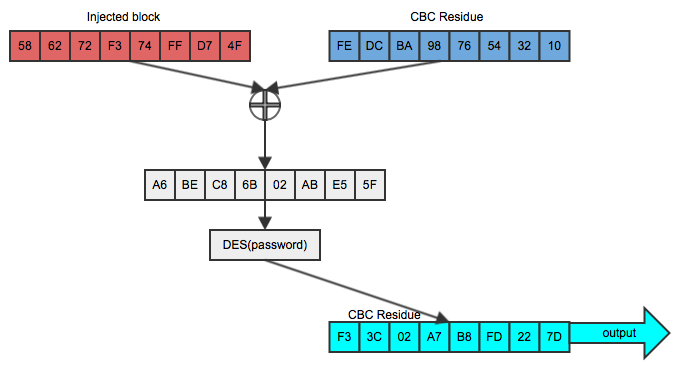
Figure 5: Successful record-splitting attack
The output is identical to the original second block (scroll back up to figure 1). Note that this works because of the commutativity of XOR; a xor b = b xor a. He didn't have to guess the password or break the encryption algorithm. In fact, Bob could have switched to a much stronger encryption algorithm like AES, but it wouldn't have mattered in this case — all Dan had to do was to be able to inject a packet whose CBC residue was known.
In fairness to TLS, Dan got fairly lucky in this case. His wife's name happened to be exactly on an 8-byte boundary and was exactly the length of one block (or maybe he was the paranoid type and deliberately married a girl with an eight character name so that her philandering would be susceptible to record splitting attacks). Still, you can probably see how this same basic idea could be used successfully against pretty much any arbitrary block of data, as long as its position in the plaintext was known. Furthermore, the history of cryptography teaches that theoretical attacks become exploitable security holes, and if you wait until the theoretical becomes practical, you'll have waited too long. After all, TLS was designed — in fact, you can say that its primary purpose is — to be resistant against attackers who have compromised the channel in exactly this way such that they can modify or insert arbitrary traffic as they please. The TLS working group drafted a fix in 2006 with TLS 1.1. The fix was simple enough, theoretically — each packet gets its own IV, and that IV is transmitted (unencrypted) at the beginning of each packet. The fact that it's transmitted unencrypted is not a security problem — by the time the attacker can see it, it's already been used.
Well, although the TLS working group took this theoretical flaw seriously, SSL implementers didn't. In September 2011, security researchers Thai Duong and Julian Rizzo made the theoretical practical with their BEAST (Browser Exploit Against SSL/TLS) attack. First, note that the 'B' in the backronym BEAST is "Browser" — their exploit isn't necessarily an attack on SSL/TLS itself, but an attack on the way it's implemented in modern browsers (and servers). The attack itself only works against browsers and HTTPS specifically. This doesn't mean, of course, that other record-splitting attacks don't exist, but this one does require a browser to work.
To understand the BEAST approach to exploiting the known-CBC problem, recall that there are two problems, from the attackers point of view, of record splitting attacks such as the one Dan mounted successfully against Bob in figure 5. The first is that the attacker has to "guess" an entire block of data to be able to discern any useful information. Suppose that, in our hypothetical scenario, Kimberly suspects Dan of cheating, and she wants to know the name of the shameless hussy (her words, not mine). In this case, she'd have to go through the big book of baby names and try the attack with every known girl's name until she got a lucky hit. The second problem, of course, is that the victim has to be tricked into inserting known plaintext into a TLS stream in the first place.
Rizzo and Duong solved the first problem in a clever way; this is really the novelty of the BEAST attack. It takes only one "hit" to determine if any given 8-byte block in the plaintext is precisely equal to the attacker's guess. If the attacker just wants to verify yes or no, then the record splitting attack is perfect. If, on the other hand, you want to determine the value of a block, you'd have to try every single one of the 2568 combinations before you found the right one — on average, 2568/2. That's a lot of searching. However, if you already know the value of the first seven characters of the block, you only need to search through, on average, 128 combinations to find the value of the last one; fewer if you can employ some heuristics (such as that the value must be an ASCII character).
So, how does one go about predicting these first 7 characters to take advantage
of the design flaw? Well, one of the problems with HTTP from a security perspective is that it, like any
useful network protocol, includes a lot of known plaintext for an attacker.
Consider a fairly standard HTTP request in figure 6:
GET /index.html HTTP/1.1
Host: mysite.com
Cookie: Session=12345678
Accept-Encoding: text/html
Accept-Charset: utf-8
Figure 6: Example HTTP request
Parts of this request are required by the protocol to be in specific places, and many other parts are easily guessable. Figure 7 shows in bold the parts that are required and in italics the part that take only a bit of guesswork to predict.
GET /index.html HTTP/1.1
Host: mysite.com
Cookie: Session=123456
Accept-Encoding: text/html
Accept-Charset: utf-8
Figure 7: Example HTTP with required or obvious portions highlighted. Required parts in bold, easily guessable parts in italics.
Here, the only really variable part of the request are the page being requested (which in a lot of cases is itself easily guessable as well) and the value of the session cookie. As it turns out, this session cookie is really the "key to the kingdom". If I, as an attacker, can determine its value, I can impersonate you using your account. So, how can I take advantage of TLS 1.0's record splitting flaw to determine it?
Recall from example 2 that I can guess the value in a block and determine
accurately whether or not my guess was correct, without compromising the secret
key that protects the session. Now, let's say that, in CBC mode, the first
78 bytes of your plaintext request are:
DES encrypted in CBC mode, using a key of password and an IV of
0x0123456789abcdef, this becomes:
GET /index.html HTTP/1.1\r\nHost: www.somesite.com\r\nCookie: Session=12345678
The hypothetical attacker would be interested in the last block,
GET /ind
ex.html
HTTP/1.1
\r\nHost
: mysite
.com\r\n
Cookie:
Session=
12345678
a7d25abbd67b2dbf
e2ade7246ea5ed5
e99063ebe430b75b
746ae5eca36e2bc3
f6f62f99a076056f
6b14704973a779ae
7fa9300d4e490cba
b6040b9542a59ad5
f9bb888ac3763722b
f9bb888ac3763722b — remember that the nature of HTTP makes it relatively
straightforward for him to determine exactly what block or blocks contain the
sensitive information, especially in the case of session cookies. Assuming
he can inject packets, he could start injecting
them starting with the value 00000000 until he hit the one that matched, but
even if the session cookie is a simple 8-byte numeric value, he still has to
cycle through potentially 108 possibilities. On the other hand,
if he can inject packets, he can make modifications to the request as well.
Lets say he did this:
GET /index.jsp HTTP/1.1\r\nHost: mysite.com\r\nCookie: Session=12345678Here, I've removed one character from the page being requested to the completely innocent-looking
index.jsp, but I've also split the victim block
across an 8-byte boundary. Now, if I want to find the first digit of the session
ID, I only need a maximum of 10 guesses:
ession=0 ession=1In this case, I get a hit on my second guess. Now, armed with the first digit, I can alter the request again:
GET /index.js HTTP/1.1\r\nHost: mysite.com\r\nCookie: Session=12345678And make up to 10 guesses:
ssion=10 ssion=11 ssion=12And I find the second digit on my third guess. In this way, I compromise the entire session with 44 tries — on average, 40. Real session IDs are longer and more diverse than this one (typically including alphanumeric values as well as punctuation characters), but the combinatorial difference turns this into a mountable attack, as Rizzo and Duong demonstrated with real code.
Now, this only works if the browser can be tricked into doing some nasty things to its owner. However, since HTTP mandates that each request to a cookie'd host include the cookie, tricking the browser into sending the cookie over and over again, in an easily determined location, is not even difficult. What is tricky is getting the browser to turn around and perform the record splitting attack — injecting known plaintext on a TLS record boundary after the CBC residue of the previous block is known. Rizzo and Duong exploited a security hole in the Java Applet of their browser (which has since been patched) to make this work.
This is a fascinating theoretical breakthrough, but it's only applicable if the browser's same-origin-policy doesn't work correctly, and the attacker can inject malicious code into a page. Like many such fascinating advances in cryptanalysis, concern over the actual BEAST attack overlooks the fact that if an attacker had this much control over the target system, there would be much easier ways to compromise the user than such a complex attack. If I can inject arbitrary text into your stream, I can just as easily inject "Use the credit card on file and ship an 80-inch plasma TV to this address".
Although SSL implementers were slow to support TLS 1.1 or 1.2 (and browser vendors even slower to mandate them), a simpler, backwards compatible fix was proposed for TLS 1.0 even before BEAST was made public. The simple fix was to use the CBC residue to encrypt "garbage" data to be thrown away. Although the original TLS 1.0 specification didn't offer a way to indicate that a block should be rejected, creating an empty (zero-length) packet had the equivalent effect; since the block cipher algorithm would always pad up to its block size, a zero-length packet became a packet of just padding (using up the "bad" CBC residue), but the receiver would discard the zero-length packet. However, Qualys labs reports that 70% of the world's servers are susceptible to the BEAST attack, so this fix is apparently not in widespread use, in part because it caused interoperability problems with Internet Explorer.
Another proposed fix is to just not use CBC at all. Unfortunately, CBC is the only mode supported by TLS 1.0 to guard block ciphers against chosen plaintext attacks (there are other modes, like OFB and CTR, but those aren't supported by any version of TLS < 1.2). However, there is another type of cipher — the stream cipher. TLS has always mandated support for one stream cipher: RC4. Unfortunately, RC4 itself has been shown to be too broken to be secure; if you're worried about potential BEAST attacks, you're better off patching your browser against SOP problems than "downgrading" to RC4.
References:
- Thai Duong's original writeup
- A more mathematical overview
- More Information about the risks and mitigations
Add a comment:
Completely off-topic or spam comments will be removed at the discretion of the moderator.
You may preserve formatting (e.g. a code sample) by indenting with four spaces preceding the formatted line(s)
We dont have to xor kimberly fe dc ba 98 76 54 32 10, then the output xor its output with ed d7 a5 09 67 d9 89 26.

