Using the Chrome Debugger Tools, part 8 - The Audits Tab
If you've been following along with this multi-part series on the Chrome debugger tools, you may
wonder by now why, if the Chrome developers are so
acutely aware of what may be the cause of poor performance of your web pages, they don't just
tell you what those things are and be done with it. Although it's sort of "cheating", they did
do quite a bit of that with the Audits tab. If you run the auditor against your page, Chrome
will look for common mistakes and in many cases even tell you where and how to correct them.
Running the audits is trivially simple — navigate to the Audits tab in the
developer tools shown in figure 1, select what sort of audits you want to run and click the Run button.
At present, there are only two sorts of audits available — Network Utilization and
Web Page Performance, although the structure of the debugger tools (and Chrome's own blog) make
it clear that the intent is to add other sorts of audits such as accessibility audits in the
future.
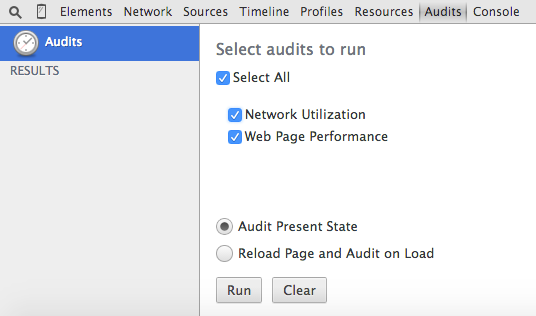
Figure 1: Selecting and running web page audits
If you open Example 1 and run both audits against it, you'll see a list of suggested improvements as shown in figure 2. I can't say definitively that this is an exhaustive list of audit suggestions — these are just all of the ones that I've come across personally. Chrome doesn't publish a list of what the audit process may find, since they're (presumedly) always working to add new ones. In some cases, the audited item is accompanied by a link to exactly where you need to go and what you need to do in order to fix it, but some of them are a bit more terse and may require a bit more investigation on your part. As you can see from figure 2, the items are ranked in order of severity with more serious items appearing at the top of the list, with a red icon.

Figure 2: Audit items
Network Utilization
If your page doesn't load quickly, it won't be effective — research has shown that users
will abandon a page after just a few seconds. The audit items in the network utilization section are targeted toward reducing
the time it takes for a user to download your page.
Understanding the items in this section requires a basic understanding of the overall web page load process
dictated by the HTTP protocol. When a web browser requests a web page from a server, the browser
first downloads the corresponding HTML resource and then begins parsing it. That HTML page almost
always includes references to other auxiliary items such as images, scripts and CSS declarations
which the browser must in turn download before the page can be fully rendered. Anything that you
can do to optimize this process will result in quicker page load and rendering times for your
site's users.
For the most part, the audit items reported in this section are targeted at server administrators
rather than web page designers.
Although the HTTP protocol was enhanced early on to allow a single connection to be kept alive and reused through multiple requests, it's still most efficient when the number of resources is minimized. Since there's really no technical reason why you'd want to maintain multiple CSS files, a quick and easy optimization is to combine them into a single file for download. You don't have to maintain them that way, assuming there's some development maintenance reason for keeping them split up; just concatenate them together before deployment. Chrome doesn't appear to trigger this rule until you have more than 3 resources of a single type.
Enable gzip compression (could save ~2.3 KB)Using GZIP compression is likewise a quick and simple way to reduce network bandwidth. Although the resource needs to be compressed by the server before transmission and then uncompressed by the browser on reception, these operations are orders of magnitude faster than the equivalent network operations. Still, Chrome doesn't start warning you about this until the potential savings are signifiant — more than a few KB per page load. It is possible that GZIP compression can actually slow down certain smaller pages, so you may want to do some profiling before blindly enabling GZIP compression but for the most part, it's a safe bet for most sites.
Leverage browser caching (set cache-expiration)The fastest page to download is one that's already there. All browsers are designed to store resources locally the first time they're downloaded and then retrieve them from the local store if possible on subsequent download requests. Thus a user will have to wait for the download the first time they visit the site, but thereafter the browser can speed up the page load quite a bit by fetching pieces of it from local cache. However, it's up to the page designer to coordinate with the browser as to which resources can be safely cached and for how long. A site's landing page might change every day, whereas common CSS files may never change. Unless the site administrator takes advantage of the cache-expiration header to notify the browser that the resource is cacheable, though, the browser will assume that the resource must be re-retrieved on each page load.
Leverage proxy caching (Cache-control: public)
If a resource has already been downloaded, as is the case when the browser has successfully cached
it, the download can be skipped entirely, saving a lot of network bandwidth. However, even if
the resource isn't available on the local browser cache, the next fastest
resource download is one that comes from "nearby", i.e. fewer network hops away. That's the concept behind Content Delivery
Networks — cache common resources on machines that are closer to the user and serve
them from there, minimizing network round-trips and speeding up page download time. Like browser
caches, though, it's incumbent on the site administrator and page designer to use the
Cache-control header to inform the proxy that the resource is safely cacheable. Note
that this is a higher bar than cache-expiration — a resource may be cacheable
for a specific user, but not at the level of a shared proxy that applies to potentially all users.
Common CSS and Javascript are good candidates for proxy-level caching.
Unlike some other items in this list that are triggered once a specific threshold is reached, Chrome appears to always remind you to reduce cookie size as long as you use them at all.
Parallelize downloads across hostnames (distribute resources across multiple hostnames)As I mentioned before, almost all web pages include links to "sub elements" such as CSS specifications, Javascript extensions, images, etc. which must be subsequently downloaded before the page can be rendered — sometimes before the page can even be previewed. One simple way a browser could potentially speed up the overall download time would be to open a new network connection for each of these subelements and download them all in parallel. Although that would definitely speed things up from the perspective of the client, it would also almost definitely crash the server as soon as any notable load was applied to it. To strike a balance between client-side performance and server stability, all browsers set a maximum number of connections per target server that they'll establish. One way a site can minimize download time, then, is to distribute its resources across multiple hosts so that the browser can safely establish more connections. This is typically done by hosting images apart from HTML content, but there's no reason that scripts like Javascript and CSS couldn't be distributed this way as well.
Serve static content from a cookieless domainWhile we're on the subject of downloading multiple resources to build a single page: HTTP cookies are pinned to a domain. The rules of HTTP state that the browser must include the value of each applicable cookie when it requests a resource from that domain. However, it would be rare for scripts and images to be dynamic dependent on values of cookies (possible, but rare). On the assumption that your images will look the same regardless of what cookies the user has set, Chrome recommends that you serve the images from a separate domain which will never have any cookies, to minimize the amount of data the browser has to send making the request in the first place. This rule doesn't appear to be triggered until you reach a certain cookie-size threshold is reached.
Specify image dimensions
This one is sort of out of place in this group; the others are focused on minimizing network
usage to speed up download time. Specifying image dimensions won't impact how long it takes to
download a page — the images have to be downloaded however big they might be — but
the user's overall perception of the page download can be impacted if image dimensions aren't
specified. Recall that Chrome (as well as any other browser) will download the HTML file first,
and the images second. Without hints as to how big the images are going to be, Chrome has a
tough choice: either wait until the images are downloaded to start rendering the page, or flow
the page with "placeholders" where the images go and run the risk of re-flowing the page when
the image dimensions are known (i.e. after they're downloaded). If you provide the image
dimensions (height and width) in all of your <img> tags, Chrome can display
the page immediately, and insert the images as they become available.
Web Page performance
It would be nice if Chrome could automate your memory profiling and tell you exactly where the
garbage collection problems were going to occur. However, it's not this advanced yet; while
Chrome has some great tools
to help you track down memory leaks in Javascript-heavy pages, you still have to do your part.
The Audits tab, on the other hand, can do some checks to make sure that you're not
making Chrome itself work harder than it would otherwise have to — anything it finds in this regard
will be listed under Web Page Performance.
Every time Chrome encounters a new CSS rule while processing a page, it must check to see if that
rule matches any elements being displayed. So, naturally, the sooner it knows which CSS rules it's
going to need to apply, the quicker page rendering will occur. As a page author, you can help in
this regard by putting all of your CSS rules in the document head, before the first HTML element
appears. Note that inline style rules such as <p style="color: red"> don't
trigger this audit rule — although you shouldn't do that anyway, for maintainability reasons.
When Javascript was new, it was common to use it to update the page as it was being rendered,
e.g.:
One side effect of this capability is that the page renderer (i.e. the browser) has to stop
rendering whenever it encounters such an inline script, evaluate it, and only once the script
has completed can it continue evaluating the remainder of the HTML. As a result, it's best to
avoid such inline scripts (web designers will make fun of you if you use them, too). They're
especially harmful in the document
<script>
document.write('<h1>You are visitor number ' + visitorNumber + '</h1>');
</script>
head because the browser can't begin downloading
any resources that follow the inline script until the script has been executed. The easiest way
to deal with this is to remove the inline script entirely — if you can't do that, at least
move it to the very bottom of the head declaration.
This one is a no-brainer — Chrome spends a lot of time comparing elements against potential CSS rule matches. Once the page has been completely rendered, if any of the CSS rules have not been triggered, Chrome assumes that they're unused and eligible for removal. Beware of false positives here, though — it's entirely possible that a dynamic Javascript-heavy page could modify a DOM element in response to a user action to cause that element to match a CSS rule. Be certain that a rule is really unused before you remove it; exercising your page a bit before running the audits can help here.
Use normal CSS property names instead of vendor-prefixed ones
The CSS standard was designed for extensibility. One of the rules of CSS is that if a browser
encountered a CSS property whose name is not recognized,
it should silently ignore that property and continue parsing the style sheet. This presents a
conundrum for a browser implementor who wants to experiment with a new CSS property, though —
what if they introduce a property name squiggliness which later becomes a conflicting
property in a subsequent version of the CSS standard?
Since CSS guarantees
that a dash-prefixed property name will never be standardized, vendors may freely experiment with
new property names as long as they prefix their names with a dash while not having to worry about
forward compatibility.
Apple and Mozilla did a lot of work improving the look of web pages while still observing standards by defining proprietary CSS property proposals. A lot of that involved new proposals for CSS properties like rounded corner
radii and animations. CSS authors who wanted to use those properties in their pages could safely
declare, say, -webkit prefixed properties which would be recognized by progressive browsers
like Safari and Chrome, but which wouldn't cause backward compatibility problems for older, less
enlightened browsers. Nowadays, though, a fair number of these webkit extensions (along with
other extensions that came from Mozilla) have been standardized, and page rendering will happen
a lot faster if you use the standard properties rather than the proprietary ones.
Now, take all of these audits with a grain of salt — just because something shows up on the audit list doesn't mean you necessarily need to do something about it. GMail, for example, shows six audit items. Google's home page shows six, three of which are "critical". Still, running the audit is a great "post-production" check to make sure that you haven't overlooked any last-minute performance items before you go live.
Part 9: The Console TabAdd a comment:
Completely off-topic or spam comments will be removed at the discretion of the moderator.
You may preserve formatting (e.g. a code sample) by indenting with four spaces preceding the formatted line(s)

