Inside the GIF file format
Last month, I presented a breakdown of the LZW algorithm, which is the compression algorithm behind the GIF (Graphics Interchange Format) image format. I stopped short of presenting the actual GIF format itself there — this article will present a full-fledged GIF decoder, using the LZW decompressor I developed last month.
GIF itself is 25 years old, the oldest image compression format still in common use. Although it has competition from the popular PNG and JPG formats, it still remains a fairly common image compression method. As you'll see, a lot of the design considerations behind the GIF format were based on the hardware of the time which itself is now archaically out-of-date, but the format in general has managed to stand the test of time.
An image, in the context of a GIF file anyway, is a rectangular
array of colored dots called pixels. Because of the way CRT
(Cathode-Ray Tube) displays and their modern successors, the
Liquid Crystal Display (LCD) are built, these pixels are actually
combinations of three separate color components; one red, one green and one
blue. By varying the intensity of the individual color components for each
pixel, any color can be represented. Deep purple, for example, is a mix of
full-intensity red and full-intensity blue. Generally speaking, the color
components can vary from 0 (not present) to 28=256 (full intensity).
Early color-capable graphics
hardware could only display 16 distinct colors at a time, but modern displays can
display any combination of red, green and blue intensities. This works out
to 224=16,777,216 distinct colors at one time — far, far more than the human
eye can actually discern. Since GIF dates back to the 1980's, when 16-color
displays were common and 224 "true color" displays were rare, GIF
is based on the notion of palettes, which the specification refers
to as color tables. Although a 16-color display
could only display 16 distinct colors at one time, the foremost app
was allowed to select which 16 colors (of the 224 possible color
component intensity combinations) these were. The GIF file format, then,
starts off by describing a palette of these color intensity
values; the image itself is then described as a series of indices into this
color palette.
Color Table:
| Index | Red | Green | Blue |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 0 | 255 | 255 |
| 2 | 0 | 0 | 128 |
| 3 | 128 | 0 | 0 |
Example 1: Indexed four-color smiley face image
Example 1 illustrates a crudely-drawn smiley face image. Since it only has four colors, it only needs four palette entries. These palette entries are drawn from a large color space, but each pixel here can be represnted using 2 bits.
This "palettizing" of the image's pixels compresses it quite a bit. It would take 3 bytes per pixel to describe an image in true-color format; by palettizing an image this way, the size of a 16-color image can be immediately reduced by a factor of 6, since it only takes 4 bits to describe each pixel. More distinct colors means less compression, but 256 colors is quite a few, and even a 256 color palette represents a 3:1 compression ratio.
GIF permits even more sophisticated compression by permitting the encoder to break the image into individual blocks. Each block may have its own color palette - in this way, an image with, say, 256 colors that occur most frequently in the upper-left quadrant can specify this quadrant as its own block, with its own palette, and a separate palette for the other quadrants. As it turns out, nobody ever took advantage of this hyper-compressive capability, but instead retrofitted it to permit GIF animation. I'll come back to this later on.
GIF compresses the index data itself even further by applying the LZW compression algorithm to these palette indices. It does so in a fairly coarse way - the indices themselves are treated as a long, linear sequence of bytes and LZW is applied to the bytes themselves. This approach fails to take into account the fact that the first pixel of any given line is more likely to be the same as the first pixel of the previous line than the last pixel of the previous line (which is how the LZW algorithm sees the pixels).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | .... | 100 |
| 101 | 102 | 103 | 104 | 105 | 106 | 107 | .... | 200 |
| 201 | 202 | 203 | 204 | 205 | 206 | 207 | .... | 300 |
| ... |
Example 2: 100-pixel-wide GIF
In Example 2, pixels 1 and 101 are far more likely to be identical than pixels 100 and 101, but the LZW algorithm will see pixel 101 following 100. In spite of this, the LZW algorithm ends up providing pretty good compression by recognizing similarities within individual lines and repeating patterns that recur from one line to the next.
Like any file format, GIF begins with a standardized header:
| Description | Size | Sample Values |
|---|---|---|
| ID tag | 3 bytes | GIF |
| Version | 3 bytes | 87a 89a |
| Width | 2 bytes | |
| Height | 2 bytes | |
| Field | 1 byte | |
| Background color index | 1 byte | |
| Pixel Aspect Ratio | 1 byte |
The next byte is the "fields" byte. The fields byte is broken down (most significant bit to least significant bit) as:
w: Marks the existence of a global color table. Recall that GIF permits the encoder to subdivide the image into individual blocks for greater compression, each with its own color table. Alternately, a single "global" color table can be given which all blocks use; if this bit is set, then the header is immediately followed by a global color table. You'll find that virtually all GIFs contain a global color table.
x: number of color resolution bits, minus 1. This is the base-2 logarithm of the number of colors that the display unit is believed to be capable of supporting — this is not the same as the number of colors in the actual GIF. If the display can only display 16 colors, and the GIF indicates that it expects the display to support 256, then the software may well just abort the display. These days, this value is informational (at best).
y: "sorted" flag. To understand the utility of the sorted flag, suppose a display capable of only displaying 16 colors is presented with a 64-color GIF. The GIF encoder can make it possible for the low-resolution display to approximate the display of the GIF by sorting the color palette by the frequency of the colors — the display can just display those colors (maybe skipping the others entirely or trying to find their closest match). This flag is set if the encoder did so. The setting of this flag isn't particularly important these days, since 16-color displays are pretty few and far between nowadays.
z: number of bits in the global color table, minus 1. So the global color table contains 2z+1 entries.
Background color index: If any pixels in the rectangular area described by this GIF are not specified this is the color to set them to. How, you may ask, would a pixel value not be set? After all, the GIF itself is described as a rectangle. Recall, however, that GIF permits the image to be subdivided into smaller blocks, which themselves don't necessarily take up the whole image display area. If for some reason the upper-left and lower-right quadrant were defined, but the rest of the block was not, some pixels would be left unset.
Pixel aspect ratio: Again this is informational (at best) — this tells the decoder what the ratio of the pixel's widths to their heights were in the original image. How a decoder might make use of this information isn't described; I'm not aware of any GIF decoder that pays any attention to it.
Parsing the GIF header, then, can be done as shown in listing 1:
typedef struct
{
unsigned short width;
unsigned short height;
unsigned char fields;
unsigned char background_color_index;
unsigned char pixel_aspect_ratio;
}
screen_descriptor_t;
/**
* @param gif_file the file descriptor of a file containing a
* GIF-encoded file. This should point to the first byte in
* the file when invoked.
*/
static void process_gif_stream( int gif_file )
{
unsigned char header[ 7 ];
screen_descriptor_t screen_descriptor;
int color_resolution_bits;
// A GIF file starts with a Header (section 17)
if ( read( gif_file, header, 6 ) != 6 )
{
perror( "Invalid GIF file (too short)" );
return;
}
header[ 6 ] = 0x0;
// XXX there's another format, GIF87a, that you may still find
// floating around.
if ( strcmp( "GIF89a", header ) )
{
fprintf( stderr,
"Invalid GIF file (header is '%s', should be 'GIF89a')\n",
header );
return;
}
// Followed by a logical screen descriptor
// Note that this works because GIFs specify little-endian order; on a
// big-endian machine, the height & width would need to be reversed.
// Can't use sizeof here since GCC does byte alignment;
// sizeof( screen_descriptor_t ) = 8!
if ( read( gif_file, &screen_descriptor, 7 ) < 7 )
{
perror( "Invalid GIF file (too short)" );
return;
}
color_resolution_bits = ( ( screen_descriptor.fields & 0x70 ) >> 4 ) + 1;
Listing 1: Parsing the GIF header
If the fields indicate that the GIF contains a global color table, it immediately follows the header. The size is given by the flags, and it indicates how many 3-byte entries are contained by the global color table; each indicates the intensity of the red, green and blue (respectively) of each index. Listing 2 illustrates the parsing of the global color table:
typedef struct
{
unsigned char r;
unsigned char g;
unsigned char b;
}
rgb;
...
static void process_gif_stream( int gif_file )
{
unsigned char header[ 7 ];
screen_descriptor_t screen_descriptor;
int color_resolution_bits;
int global_color_table_size; // number of entries in global_color_table
rgb *global_color_table;
...
if ( screen_descriptor.fields & 0x80 )
{
int i;
// If bit 7 is set, the next block is a global color table; read it
global_color_table_size = 1 <<
( ( ( screen_descriptor.fields & 0x07 ) + 1 ) );
global_color_table = ( rgb * ) malloc( 3 * global_color_table_size );
// XXX this could conceivably return a short count...
if ( read( gif_file, global_color_table, 3 * global_color_table_size ) <
3 * global_color_table_size )
{
perror( "Unable to read global color table" );
return;
}
}
Listing 2: Parsing the global color table
This concludes the header portion of the GIF file. Following the header
is a series of blocks. Each block is marked off by a one-byte block-type
identifier. The most important of these is the image descriptor
block 0x2C — this is where the indices of the actual image are stored.
The next-most-important block type is the trailer block 0x3B
which indicates the end of a GIF - if this trailer block isn't encountered
before the end of the file, the file has been somehow corrupted.
So, once the main header and the global color table (if present, although for all practical purposes it always will be) have been parsed, the next thing to do is to start looking for blocks and parsing them according to their types as shown in listing 3:
#define IMAGE_DESCRIPTOR 0x2C
#define TRAILER 0x3B
...
static void process_gif_stream( int gif_file )
{
unsigned char header[ 7 ];
screen_descriptor_t screen_descriptor;
int color_resolution_bits;
int global_color_table_size; // number of entries in global_color_table
rgb *global_color_table;
unsigned char block_type = 0x0;
...
while ( block_type != TRAILER )
{
if ( read( gif_file, &block_type, 1 ) < 1 )
{
perror( "Invalid GIF file (too short)" );
return;
}
switch ( block_type )
{
case IMAGE_DESCRIPTOR:
if ( !process_image_descriptor( gif_file,
global_color_table,
global_color_table_size,
color_resolution_bits ) )
{
return;
}
break;
case TRAILER:
break;
...
default:
fprintf( stderr, "Bailing on unrecognized block type %.02x\n",
block_type );
return;
}
}
}
Listing 3: Parsing the data blocks
The image descriptor block itself begins with a 9-byte header structure:
| image_left_position | 2 bytes |
| image_top_position | 2 bytes |
| image_width | 2 bytes |
| image_height | 2 bytes |
| fields | 1 byte |
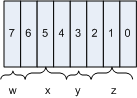
The fields, again, are split up as:
| w: | local color table flag |
|---|---|
| x: | interlace flag |
| y: | sorted flag |
| z: | size of local color table |
One bit that appears in this flags byte that doesn't have an analog in the
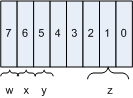
flags byte defined in the global header is the interlace
flag. Remember that GIF is optimized for slow display hardware — the idea
behind interlacing is that the display can show the image in rough format
early in the parsing process, and progressively display more and more detail
until the image has been completely processed. Therefore, if the interlace
flag is set, then the lines of the image will be included out of order: first,
every 8th line. Second, every 8th line, starting from the fourth. Third,
every 4th line, starting from the second, and finally every other line,
completing the image.
Example 3: Interlacing of a 26-line GIF
Example 3 illustrates how an interlaced file is stored. The idea is that the lines marked in green will be read, and displayed, first, followed by the ones marked in yellow, then the ones marked in blue and finally all remaining lines. This way, the user can get an idea what the picture is going to look like before it has completely downloaded; if it's not what he was expecting, he can abort the remainder of the download and save some bandwitdth. This made a lot more sense back in the days of 28.8 modems — these days, the whole image will have downloaded before the user has a chance to get an idea of what he's looking at. Still, you'll find quite a few interlaced GIF files floating around on the internet, even today.
Ignoring the parsing of the LCT, the image descriptor header is parsed as shown in listing 4:
typedef struct
{
unsigned short image_left_position;
unsigned short image_top_position;
unsigned short image_width;
unsigned short image_height;
unsigned char fields;
}
image_descriptor_t;
...
static int process_image_descriptor( int gif_file,
rgb *gct,
int gct_size,
int resolution_bits )
{
image_descriptor_t image_descriptor;
int disposition;
// TODO there could actually be lots of these
if ( read( gif_file, &image_descriptor, 9 ) < 9 )
{
perror( "Invalid GIF file (too short)" );
disposition = 0;
goto done;
}
// TODO if LCT = true, read the LCT
...
disposition = 1;
done:
return disposition;
}
Listing 4: Parsing the image descriptor header
Following the image descriptor header, still logically contained inside the
image descriptor block itself, is a series of data sub-blocks.
These data sub-blocks are the LZW-compressed indices into the active color
table — if the image descriptor block contained a local color table,
these are the indices into the local color table; otherwise they are indices
into the global color table. The data sub-blocks themselves are further
subdivided into 255-byte chunks; each chunk declares its length as its first
single byte. Clearly, since a single GIF can (theoretically) be 655356x65536=4,294,967,296
pixels, almost all image descriptors will be made of multiple data sub-blocks,
even though they are compressed. However, the decoder doesn't have enough
information at this point to be able to tell how many bytes of compressed
data follow. Therefore, the decoder must instead keep reading data sub-blocks
until a zero-length sub-block in encountered, indicating that the end of the
compressed data.
These sub-blocks (of compressed data) can be read into memory as shown in listing 5. Here, I've opted to slurp the whole mess into memory by making repeated calls to realloc — any GIF implementation worthy of being taken seriously would instead be decompressing this data as it was being read, but this implementation is simpler to understand.
static int read_sub_blocks( int gif_file, unsigned char **data )
{
int data_length;
int index;
unsigned char block_size;
// Everything following are data sub-blocks, until a 0-sized block is
// encountered.
data_length = 0;
*data = NULL;
index = 0;
while ( 1 )
{
if ( read( gif_file, &block_size, 1 ) < 1 )
{
perror( "Invalid GIF file (too short): " );
return -1;
}
if ( block_size == 0 ) // end of sub-blocks
{
break;
}
data_length += block_size;
*data = realloc( *data, data_length );
// TODO this could be split across block size boundaries
if ( read( gif_file, *data + index, block_size ) <
block_size )
{
perror( "Invalid GIF file (too short): " );
return -1;
}
index += block_size;
}
return data_length;
}
static int process_image_descriptor( int gif_file,
rgb *gct,
int gct_size,
int resolution_bits )
{
int compressed_data_length;
unsigned char *compressed_data = NULL;
...
if ( read( gif_file, &image_descriptor, 9 ) < 9 )
{
perror( "Invalid GIF file (too short)" );
disposition = 0;
goto done;
}
compressed_data_length = read_sub_blocks( gif_file, &compressed_data );
...
done:
if ( compressed_data )
free( compressed_data );
return disposition;
}
Listing 5: Reading the data sub-blocks
At this point, the compressed data is contained entirely in the buffer
specified by compressed_data. The next thing to do, of course,
is to decompress it. This could almost be done using the decompress
implementation from last month's article. There are a few modifications that
need to be made for it to work with compressed GIF data, though:
-
Last month's implementation used
strcmpandstrcatto imlplement the LZW dictionary. This won't work for GIF indices, because they contain embedded zero's which C's string operations interpret as "end of string". - That implementation assumed that the compressed data started with 8-bit codes and expanded to 9 bits when the dictionary filled up. In fact, GIF allows variable starting sizes, all the way down to four-bit codes.
To solve the first problem, the dictionary itself must be reimagined. Rather
than being an array of strings, the dictionary is implemented as a structure
of pointers. Recall from last month that when a new dictionary index was
encountered, it was created by concatenating (using strcat) the
most recently read code on top of the previous dictionary entry. A more
flexible approach is to define a structure that allows each entry to point
to its predecessor, as shown in listing 6:
typedef struct
{
unsigned char byte;
int prev;
int len;
}
dictionary_entry_t;
Listing 6: pointer-based dictionary structure
Now, a string of 5 0x0 bytes will be represented in memory as:

Each of these structures will be pointed to by a dictionary entry as well;
the index into the dictionary, which is now an array of pointers to
dictionary_entry_t, is the expansion code read from the file. So, if the
first five bytes were all 0's (which is pretty common) and the global color
table contained 64 entries:
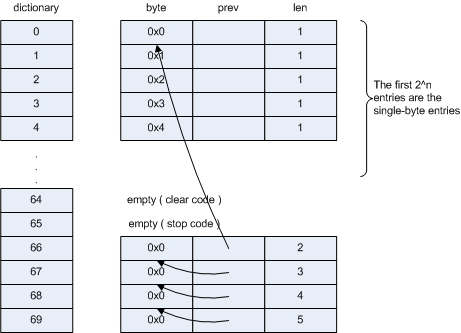
Here, the length declaration is just a convenience; it's not strictly necessary (and most GIF implementation omit it to speed up decompression). If the code 69 is encountered in the data stream, the decompressor would look up dictionary[ 69 ], find that it's byte was 0, emit a 0, and then follow the backpointer to &dictionary[ 68 ], emit another 0, and so on. However, the entries are built up this way "backwards", so it's necessary to emit them in reverse order. Most GIF implementations push the bytes onto a stack and then pop them back off to do the actual decompression; I instead keep track of the length so I know how many bytes forward in the output buffer to jump ahead when emitting the first code.
Once this is squared away, solving the second problem — that of variably
sized LZW codes — is simple: just pass
the starting code size into the uncompress routine. Listing 7
is the completed GIF-friendly uncompress routine; compare this to last month's
text-based implementation. Notice that there's a hardcoded limit of 12-bit
codes; once the dictionary expands to 212=4,096 entries, it is not
permitted to grow any further. It's up to the encoder to decide if the active
dictionary is still doing a good job of compressing, or if it should send
a clear code and restart from scratch.
int uncompress( int code_length,
const unsigned char *input,
int input_length,
unsigned char *out )
{
int maxbits;
int i, bit;
int code, prev = -1;
dictionary_entry_t *dictionary;
int dictionary_ind;
unsigned int mask = 0x01;
int reset_code_length;
int clear_code; // This varies depending on code_length
int stop_code; // one more than clear code
int match_len;
clear_code = 1 << ( code_length );
stop_code = clear_code + 1;
// To handle clear codes
reset_code_length = code_length;
// Create a dictionary large enough to hold "code_length" entries.
// Once the dictionary overflows, code_length increases
dictionary = ( dictionary_entry_t * )
malloc( sizeof( dictionary_entry_t ) * ( 1 << ( code_length + 1 ) ) );
// Initialize the first 2^code_len entries of the dictionary with their
// indices. The rest of the entries will be built up dynamically.
// Technically, it shouldn't be necessary to initialize the
// dictionary. The spec says that the encoder "should output a
// clear code as the first code in the image data stream". It doesn't
// say must, though...
for ( dictionary_ind = 0;
dictionary_ind < ( 1 << code_length );
dictionary_ind++ )
{
dictionary[ dictionary_ind ].byte = dictionary_ind;
// XXX this only works because prev is a 32-bit int (> 12 bits)
dictionary[ dictionary_ind ].prev = -1;
dictionary[ dictionary_ind ].len = 1;
}
// 2^code_len + 1 is the special "end" code; don't give it an entry here
dictionary_ind++;
dictionary_ind++;
// TODO verify that the very last byte is clear_code + 1
while ( input_length )
{
code = 0x0;
// Always read one more bit than the code length
for ( i = 0; i < ( code_length + 1 ); i++ )
{
// This is different than in the file read example; that
// was a call to "next_bit"
bit = ( *input & mask ) ? 1 : 0;
mask <<= 1;
if ( mask == 0x100 )
{
mask = 0x01;
input++;
input_length--;
}
code = code | ( bit << i );
}
if ( code == clear_code )
{
code_length = reset_code_length;
dictionary = ( dictionary_entry_t * ) realloc( dictionary,
sizeof( dictionary_entry_t ) * ( 1 << ( code_length + 1 ) ) );
for ( dictionary_ind = 0;
dictionary_ind < ( 1 << code_length );
dictionary_ind++ )
{
dictionary[ dictionary_ind ].byte = dictionary_ind;
// XXX this only works because prev is a 32-bit int (> 12 bits)
dictionary[ dictionary_ind ].prev = -1;
dictionary[ dictionary_ind ].len = 1;
}
dictionary_ind++;
dictionary_ind++;
prev = -1;
continue;
}
else if ( code == stop_code )
{
if ( input_length > 1 )
{
fprintf( stderr, "Malformed GIF (early stop code)\n" );
exit( 0 );
}
break;
}
// Update the dictionary with this character plus the _entry_
// (character or string) that came before it
if ( ( prev > -1 ) && ( code_length < 12 ) )
{
if ( code > dictionary_ind )
{
fprintf( stderr, "code = %.02x, but dictionary_ind = %.02x\n",
code, dictionary_ind );
exit( 0 );
}
// Special handling for KwKwK
if ( code == dictionary_ind )
{
int ptr = prev;
while ( dictionary[ ptr ].prev != -1 )
{
ptr = dictionary[ ptr ].prev;
}
dictionary[ dictionary_ind ].byte = dictionary[ ptr ].byte;
}
else
{
int ptr = code;
while ( dictionary[ ptr ].prev != -1 )
{
ptr = dictionary[ ptr ].prev;
}
dictionary[ dictionary_ind ].byte = dictionary[ ptr ].byte;
}
dictionary[ dictionary_ind ].prev = prev;
dictionary[ dictionary_ind ].len = dictionary[ prev ].len + 1;
dictionary_ind++;
// GIF89a mandates that this stops at 12 bits
if ( ( dictionary_ind == ( 1 << ( code_length + 1 ) ) ) &&
( code_length < 11 ) )
{
code_length++;
dictionary = ( dictionary_entry_t * ) realloc( dictionary,
sizeof( dictionary_entry_t ) * ( 1 << ( code_length + 1 ) ) );
}
}
prev = code;
// Now copy the dictionary entry backwards into "out"
match_len = dictionary[ code ].len;
while ( code != -1 )
{
out[ dictionary[ code ].len - 1 ] = dictionary[ code ].byte;
if ( dictionary[ code ].prev == code )
{
fprintf( stderr, "Internal error; self-reference." );
exit( 0 );
}
code = dictionary[ code ].prev;
}
out += match_len;
}
}
Listing 7: Complete binary-friendly uncompress implementation
I won't go into too much detail about how this works, since I covered it pretty thoroughly last month.
But wait - how does the caller of uncompress know how many
bits the decompressor should start reading? GIF actually mandates that the
first byte of the image descriptor's data area (before the data sub-blocks
themselves) be a single byte indicating how long the first code is.
unsigned char lzw_code_size;
...
if ( read( gif_file, &lzw_code_size, 1 ) < 1 )
{
perror( "Invalid GIF file (too short): " );
disposition = 0;
goto done;
}
compressed_data_length = read_sub_blocks( gif_file, &compressed_data );
Listing 8: reading the LZW starting code size
With uncompress defined, and the starting code length known,
the image descriptor processor can now decompress the index data.
int uncompressed_data_length = 0;
unsigned char *uncompressed_data = NULL;
...
compressed_data_length = read_sub_blocks( gif_file, &compressed_data );
uncompressed_data_length = image_descriptor.image_width *
image_descriptor.image_height;
uncompressed_data = malloc( uncompressed_data_length );
uncompress( lzw_code_size, compressed_data, compressed_data_length,
uncompressed_data );
disposition = 1;
...
done:
if ( compressed_data )
free( compressed_data );
if ( uncompressed_data )
free( uncompressed_data );
return disposition;
}
Listing 9: Invoking uncompress
And that's it - displaying the image is now a matter of indexing the
color table and (if necessary) de-interlacing the lines of the data.
so, you may legitimately be wondering why there is more than one block type
defined when the image descriptor block type contains the entire
image. The GIF '87 standard recognized that the specification might need to be
expanded later, so a special block type 0x21 was included to allow for extensions.
An extension block first includes a single byte indicating what type of
extension it describes. The next byte indicates the length of the extension
— by including the length of the extension as a standard part of the
extension, decoders that don't recognize the extension can skip over it, but
still properly process the file. The remaining bytes of the extension are,
of course, specific to the type of the extension. All extensions are followed
by data sub-blocks, formatted exactly the same as those in the image
data itself — if the extension doesn't have any associated data, it will
be followed by a single 0-byte data sub-block.
GIF '87 didn't define any extensions, but GIF '89 codified four: plaintext, comment, application-specific, and graphic control extension.
Comment extension: This extension allowed for variable-length text to be included as a read-only comment inside the GIF stream. This comment was not supposed to be displayed onscreen and it wasn't clarified exactly how the user might go about viewing it. The use of this extension is rare.
Text extension: Like the comment extension, this extension allowed for textual data to be included inside a GIF. Unlike the comment extension, however, this textual data was meant to be overlayed on top of this image as part of its display. Since the encoder has no way to specify font data (in fact, this extension only permits fixed-width fonts, so variable-width fonts or those that permit, say, kerning is not permissible), this is also very rare. I'm not aware of any GIF decoder that honors it.
Application Specific: This extension allows for arbitrary data to be stuffed into a GIF; it consists of 8 bytes that identify an application, and 3 bytes indicating a version. The data that follows in the subblocks is, obviously, dependent on the application ID.
The last, and most complex, extension type is the graphic control extension.
Remember that I mentioned that nobody uses the multiple-block capability of
GIF to hyper-compress an image file — instead, this was used to create
animated image files. Althought the GIF87a specification states that, when
multiple image blocks are encountered, "There is no pause between the images.
Each is processed immediately as seen by the decoder"
, most GIF decoders
overlayed images with delays to create the illusion of animation. Since the
software of the day was pretty slow to begin with, I suspect that this
animation capability was more of an accident, but it became very popular —
so popular that today, there are quite a few people who believe that GIF
means animated GIF.
The problem was, there was no standard way to indicate how much time should pass between frames of these animations. GIF89 embraced this and codified it with the graphic control extension. This extension is very common, not only with animated GIFs — you'll encounter these all the time. The graphic control extension starts with a fields byte:
| r | r | r | x | x | x | y | z |
| r: | reserved, set to 0 |
| x: | disposal method. This indicates what the decoder should do in between the display of separate frames; should it blank out the display area or not? |
| y: | user input flag. If not set, the GIF animation should display automatically; otherwise, the user is expected to click between animation frames. |
| z: | transparency: if true, then the last byte of the extension is a transparency index. |
The flags byte is followed by a 2-byte delay time (in hundredths of a second) between frames and a single-byte transparency index; this index should not be overlayed so that the underlying frame can "show through".
To process these extension types, add a new block type as shown in listing 10:
#define EXTENSION_INTRODUCER 0x21
#define IMAGE_DESCRIPTOR 0x2C
...
static void process_gif_stream( int gif_file )
{
...
switch ( block_type )
{
case EXTENSION_INTRODUCER:
if ( !process_extension( gif_file ) )
{
return;
}
break;
case IMAGE_DESCRIPTOR:
Listing 10: Parsing extension blocks
And then process the extensions themselves as shown in listing 11:
#define EXTENSION_INTRODUCER 0x21
#define IMAGE_DESCRIPTOR 0x2C
#define TRAILER 0x3B
#define GRAPHIC_CONTROL 0xF9
#define APPLICATION_EXTENSION 0xFF
#define COMMENT_EXTENSION 0xFE
#define PLAINTEXT_EXTENSION 0x01
typedef struct
{
unsigned char extension_code;
unsigned char block_size;
}
extension_t;
typedef struct
{
unsigned char fields;
unsigned short delay_time;
unsigned char transparent_color_index;
}
graphic_control_extension_t;
typedef struct
{
unsigned char application_id[ 8 ];
unsigned char version[ 3 ];
}
application_extension_t;
typedef struct
{
unsigned short left;
unsigned short top;
unsigned short width;
unsigned short height;
unsigned char cell_width;
unsigned char cell_height;
unsigned char foreground_color;
unsigned char background_color;
}
plaintext_extension_t;
static int process_extension( int gif_file )
{
extension_t extension;
graphic_control_extension_t gce;
application_extension_t application;
plaintext_extension_t plaintext;
unsigned char *extension_data = NULL;
int extension_data_length;
if ( read( gif_file, &extension, 2 ) < 2 )
{
perror( "Invalid GIF file (too short): " );
return 0;
}
switch ( extension.extension_code )
{
case GRAPHIC_CONTROL:
if ( read( gif_file, &gce, 4 ) < 4 )
{
perror( "Invalid GIF file (too short): " );
return 0;
}
break;
case APPLICATION_EXTENSION:
if ( read( gif_file, &application, 11 ) < 11 )
{
perror( "Invalid GIF file (too short): " );
return 0;
}
break;
case 0xFE:
// comment extension; do nothing - all the data is in the
// sub-blocks that follow.
break;
case 0x01:
if ( read( gif_file, &plaintext, 12 ) < 12 )
{
perror( "Invalid GIF file (too short): " );
return 0;
}
break;
default:
fprintf( stderr, "Unrecognized extension code.\n" );
exit( 0 );
}
// All extensions are followed by data sub-blocks; even if it's
// just a single data sub-block of length 0
extension_data_length = read_sub_blocks( gif_file, &extension_data );
if ( extension_data != NULL )
free( extension_data );
return 1;
}
Listing 11: Parsing the extensions
Of course, in this case, all I'm doing is parsing the data; I'm not interpreting it or doing anything with it. Notice that in this case, I'm hardcoding the lengths of each extension structure — this is, strictly speaking, unnecessary, since the length is indicated by a byte in the extension header itself. I'm also terminating on an unrecognized extension, in violation of the specification; I should just skip over them. The next step would be to expand the indices into an actual image and display it, while honoring transparency and animation specifications. I'll leave that to the real GIF decoders; by now, you should have a very good understanding of the ins and outs of the GIF image format.
References:- Terry Welch "A Technique for High-Performance Data Compression", IEEE Computer, June 1984
- The GIF '89 Specification
Downloads: The source code for this article
Add a comment:
Completely off-topic or spam comments will be removed at the discretion of the moderator.
You may preserve formatting (e.g. a code sample) by indenting with four spaces preceding the formatted line(s)
Sarjus-MacBook-Air:Desktop sarju$ ./a.out image2.gif
code = ef0, but dictionary_ind = d17
Can you help us in decoding this further.
Unfortunately it seems you stop right before decoding the display of animation - which to me is the most difficult part!
Maybe you would consider doing part 2? Starting where you left off?
Cheers!
when I did that ,I have a problem when the size of dictionary need to be expanded ?
OK, as I understood in 2 color gif each pixel is represented with 2 bits (sort of using dummy zero bit before actual one), so 01 means pixel of color 1 and 00 means pixel of color 0.
what I see in dump is:
offset 0x45 from beginning:
0x4c 0b01001100
0x80 0b10000000
0x68 0b01101000
0xcb 0b11001011
I try to decode it:
100 reset
001
001 add dict. entry 110: 01,01
000 add dict. entry 111: 01,00
000 add dict. entry 1010: 00,00
expand code size to 4 bits
next code is
0001 ... bah...
I'd expect it to be 1010
So I don't understand it completely. I don't see how there will be 5 zeros after 2 ones.
001 decode 1
001 add dict entry 110: 1,1, decode 1
000 add dict entry 111: 1,0, decode 0
1000 add dict entry 1000: 0,0, decode 0,0
1000 add dict entry 1001: 0,0,0, decode 0,0
0110 add dict entry 1010: 0,0,1, decode 1,1
1,1,0,0,0,0,0,1,1
I do love your suspicion that the Animated GIF feature started as a coincidental byproduct of slow computers/networks. But the inclusion of the x/y offset fields for individual frames to me sounds like GIF actually was intended for animations. The GIF data structure actually is identical to that of basic 2D sprites.
The biggest issue I was able to find is that this does not support the transparency of pixels, which I think can happen in single-frame GIFs.
Another less important improvement would be supporting decoding multi-frame GIFs. This is very trivial if you know what needs to be added. The only thing you need to add is discard methods which are quite easy once you understand what they are.

